
サイト内のあるディレクトリ(フォルダ)やページは検索エンジンの検索結果に表示したくないというときに使われるのが「robots.txt」というファイルです。
これはただのテキストファイルですがここには検索エンジンのクローラーを制御するための特別な命令を書くことでクローラーの動作を制限することが可能です。
ここではrobots.txtにどのような役割があるのかということと具体的な書き方について解説します。
robots.txtの役割
robots.txtの役割は一言でいえば検索エンジンのクローラーに特定のファイルやディレクトリを「クロール」しないように命令することです。
検索エンジンはWeb上にある膨大なページ情報を調べるためにクローラー(またはロボット)というプログラムを使って定期的にWeb上を巡回してページ情報を集めています。
このWeb上のページ情報を集める作業が「クロール」と呼ばれ、クローラーによって集められたページ情報が検索エンジンに伝えられ、データベース上にそのページが登録されることを「インデックスされる」と言います。
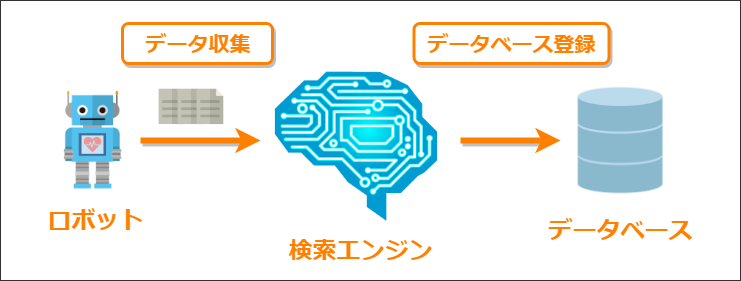
このクローラーへ特定のファイルやディレクトリのクロールをブロックするのがrobots.txtというファイルの役割です。
ではクロールをブロックすることで何の役に立つかというと次のような利点があります。
- 自動生成される質の低いコンテンツのインデックスを防げる
カテゴリごとやタグごとのまとめページはGoogleにとって質の悪いページとみなされるのでそれらをインデックスすることを回避できる
- 検索結果に特定のページを表示させないことができる
どうしても検索結果に表示したくないページがある場合はそのページを検索結果から除外することも可能
- 効率よくクロールさせることができる
無駄なファイルやディレクトリを除外することで効率よくクロールしてもらえる
このように質の悪いページや検索結果に表示したくないページをクロール対象から除外し、クローラーが効率よくクロールできるように助けるのがrobots.txtの役割です。
robots.txtの書き方・構文
クローラーに正しい命令を出すための正しいrobots.txtのルールや構文は次の通りです。
設置場所
まずrobots.txtは必ずサイトのルートディレクトリに「robots.txt」という名前で設置しなくてはなりません。文字コードはUTF-8に設定しておくと安全です。
それ以外のサブディレクトリなどに設置してもクローラーには正しく認識されないので注意しましょう。
正しい設置例
間違った設置例
またrobots.txtにクローラーがアクセスできなくてはならないのでrobots.txtにアクセス制限がかかっていないかのチェックも必要です。
基本の書き方
robots.txtでは次の2行が命令の最小単位になります。
User-Agent: *
Disallow:
まず「User-Agent」にクローラーの種類、その次の行で「Disallow」でクローラーに対してクロールを許可したくないファイルやディレクトリのURLを指定します。
robots.txtではこの2つの行がクロールへの1つの命令として扱われ、複数の命令を書くことが可能です。
User-Agentの書き方
クローラー指定するためのUser-Agentにはクロールをブロックしたい検索エンジンのクローラー名を記述します。
例えばGoogleのクローラーをブロックする場合は次のように記述します。
検索エンジンごとにクローラーの名前は違うので特定のクローラーをブロックしたい場合はまずその名前を調べる必要があります。
また検索エンジンごとでも用途に応じたクローラーが複数巡回していて、たとえばGoogleの場合は次にページで紹介されているように画像用や広告用などで複数のクローラーが動いています。
https://support.google.com/webmasters/answer/1061943?hl=ja
もし特定のクローラーではなく全てのクローラーに対してブロックしたいなら次のように「*」を使われます。
Disallowの書き方
robots.txt内でDisallowの後にファイルやディレクトリのパスを書くとUser-Agentで指定したクローラーに対してそのファイルやフォルダをクロール対象から外すことができます。
この書き方には次のようなルールがあります。
全てのファイル・ディレクトリをブロック
サイト内にある全てのファイルを全てのクローラーに対してブロックしたい場合はDisallowのあとに「/」を書きます。
Disallow: /
これでサイト全体がクローラーにクロールされず検索エンジンにもインデックスされないようになります。
ディレクトリのブロック
特定のディレクトリとその中にある全てのファイル・ディレクトリをブロックしたい場合はDisallowの後に「/[ディレクトリ名]/」のように記述します。
例えばルートディレクトリのすぐ下にある「xxx」というサブディレクトリ全てのファイルやを全てのクローラーに対してブロックしたいなら次のように書きます。
robots.txtの記述例
Disallow: /example/
ブロックされるURL例
xxx.com/example/index.php
xxx.com/example/subdir/index.php
複数ディレクトリをブロック対象に含めたい場合は次のようにDisallowを複数行にわたって書くことでそれらのディレクトリ内のファイルとディレクトリをブロック可能です。
robots.txtの記述例
Disallow: /example1/
Disallow: /example2/
Disallow: /example3/
また次のように最後の「/」がない場合はその名前から始まる全てのファイルとディレクトリがブロックされるようになります。
robots.txtの記述例
Disallow: /ex
ブロックされるURL例
example.com/example.html/
example.com/example-1.png/
最後のスラッシュ「/」があるとないとでは意味が大きく違ってしまうのでスラッシュの有無には注意が必要です。
サブディレクトリのブロック
もし2階層以上のサブディレクトリを指定する場合は「/」の後にそのディレクトリのルートディレクトリに対する相対パスを記述します。
例えばルートディレクトリの下にある「/example/subdir」というディレクトリを全てのクローラーに対してブロックする場合は次のような記述になります。
robots.txtの記述例
Disallow: /example/subdir/
ブロックされるURL例
xxx.com/example/subdir/index.php
以上がrobots.txtの書き方の基本的なルールです。
robots.txtのテストに便利なツール
robots.txtにはこのように決まった書き方(構文)があります。
なので正しく動作させるには必ずその構文に沿って書かないといけません。
でもrobots.txtの構文を初めから完璧に覚えるなんて大変ですよね。
そんな時に役立つのが「robots.txtテスター」というツール
これはSearch Consoleの一機能で、次の画像のように文法ミスを指摘してくれます。

またURLのブロックのテストする機能などもあって本当に便利です。
詳しい使い方については次の記事でまとめたのでご覧ください。


robots.txtの文法チェックやURLのブロックテストのやり方を解説しました。
まとめ
検索エンジンに表示させたくないページがあったり、クローラーが効率よくクロールを行えるようにするのにrobots.txtは役立ちます。
ただクローラーの指定やどのファイルやディレクトリをブロックするかの命令には厳密なルールがあるので構文を間違えずに正しく記述することが大事です。
以上ここではrobots.txtの役割と書き方についてでした。
フク郎
最新記事 by フク郎 (全て見る)
- トレンドブログが資産に?放置でアクセス急増の事例 - 3月 14, 2024