The post robots.txtテスターの使い方とクロールエラーがないか調べる方法 first appeared on Fukuro Press.
]]>
robots.txt はクローラーへの命令を記述できるテキストファイルのこと
このファイルに色々な命令を書くことで検索エンジンの表示結果から特定のページを1つずつまたはまとめてブロックできます。
ですが便利な反面、重要なファイルなので構文エラーがあるとページが正常にインデックスされないなどの悪影響が出ることも・・・
そんなミスを防ぐのに有効なのが robots.txtテスター というツールです。
ここではそのツールの使い方について詳しく解説していきます。
robots.txtテスターとは?
最初にrobots.txtテスターとは何なのかについて簡単に説明します。
冒頭でも書いたように robots.txt は検索エンジンのクローラーに対しての命令が書かれたテキストファイルのことです。
このファイルが使われる用途は例えば・・・
- 質の悪いページがインデックス登録されるのを防ぎたい場合
- 特定の人にだけ特定のページを公開させたい場合
・・・などなど
インデックスしたくないページがあるときに「そのページはクロールしてはダメ!」とクローラーに指示するために使われることが多いです。
詳しい書き方などについては次の記事でも解説したので、そちらをどうぞ


そしてこのrobotx.txtは拡張子が「.txt」なのでテキストファイルです。
テキストファイルなのですがクローラーは人間ではないので人間の言葉で書いても理解できません。ある決まりに従ったルールつまり「構文」通りに書かなければクローラーは理解してくれないということです。
逆に人間がその構文が正しいかどうか判断するとなると今度は人間がrobots.txtの構文について学ばなくてはならなくなります。
確かに正しいrobots.txtを書くには構文の知識がある程度は必要になりますが、人間はロボットでないので必ず間違いは起きてしまいます。そしてそれを気づけないかもしれません。
そんな時に役立つのがSearch Consoleの「robots.txtテスター」というツール
このツールにはrobots.txtの編集に役立つ次の機能がついています。
- 構文エラーの確認
- ブロックされているURLの確認
- robots.txtの送信
人間がこの作業を全てやろうとすると大変ですが、robots.txtテスターを使うとその作業を代わりにやってくれるのでとても便利です。
robots.txtテスターの使い方・機能
では、robots.txtテスターを実際に使ってみましょう。
まずSearch Consoleにアクセスしてrobots.txtの編集がしたいサイトを選びます。

サイトのダッシュボードが開いたら左のメニューの中にある「クロール」と書かれた項目をクリックしてメニューを展開

「クロール」を展開したらその中にある「robots.txtテスター」をクリック

すると次の画像のようなrobots.txtテスター画面画面が開きます。
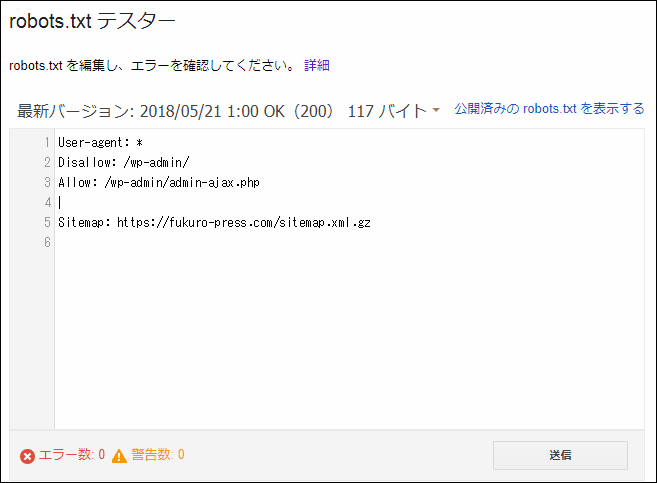
このrobots.txtテスターで使える機能は次の3つ
- robots.txtの構文チェック
- URLがブロックされているかのテスト
- robots.txtの送信
この3つの使い方について順に紹介していきます。
robots.txtの構文チェック
robots.txtは検索エンジンのクローラーが見て理解できる一定のルールつまり構文に従って書かなくてはなりません。
ただ構文エラーやささいなミスというのは人間が気付きにくいので、robots.txtテスターには次のようにこれをチェックしてエラーまたは警告を出してくれる機能があります。
エラーチェック
例えばrobots.txt内で構文エラーとなる次のような1行を書いたとします。
Disarrow: /example/
これは「Disallow」を間違えて「Disarrow」と書いてしまっているので構文エラーです。
このようなエラーがあるとその行の前に次のようにその行の前にエラーマークが付きます。

案外こういう綴りミスというのは人間が気付きにくいものなので、エラーを表示してくれる機能は便利かもしれませんね。
警告
robots.txtテスターは構文的にはエラーではないけど正しい構文ではない場合には警告も表示する機能もついています。
例えば構文的には「Disallow」の次にはコロン(:)が必要ですが、それを次のように省いてしまったとします。
Disallow /example/
このような正しくない構文が見つかった場合、テスターではその行に次のような警告マークが表示されます。

そして警告マークにホバーすると具体的にどこがダメなのかという点も指摘してくれます。

このようにテスターには編集画面上で構文エラーや警告を表示する機能があるので、正しいrobots.txtを書くのに役立つことでしょう。
URLがブロックされているかのテスト
このツールには特定URLがブロックされているか確認できる機能もあります。
その使い方は次の通り
まずテスター画面から次の画像のようなフォームを探しましょう。

そして例えば次のURLがブロックされているかどうか確認したいとします。
https://fukuro-press.com/wp-admin/
その場合はまず次のようにテキスト欄にドメイン名以下の相対パスつまりここでは「wp-admin/」と入力します。

URLを入力したら「テスト」ボタンを押しましょう。

もしそのURLがブロック済みなら次のように「ブロック済み」というメッセージが、

もしブロックされていないなら次のように「許可済み」とメッセージが表示されます。

robots.txtの内容だけだとどのURLがブロックされているのかが具体的にイメージしずらいので、その確認にこの機能が便利です。
ファイルの中身を見ても良く分からないならこの機能がかなり役に立つかもしれません。
robots.txtの送信
robots.txtテスターには編集画面がありますが、直接この画面上ではrobots.txtの内容を更新することができません。
ではどうするかというとまずテスターの編集画面右下にある「送信」ボタンを押します。

すると次のように更新手順が表示されるので、その指示に従ってrobots.txtをダウンロードしてバージョンを確認しGoogleに更新をリクエストしましょう。
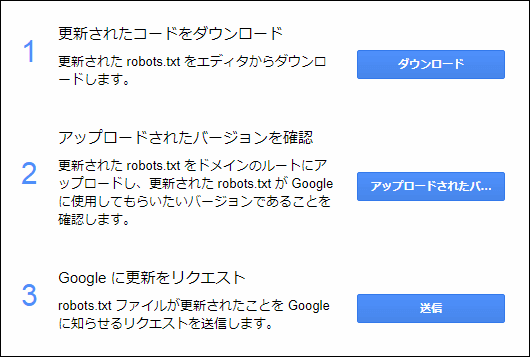
ただ単にrobots.txtをサーバーにアップロードしただけでは不十分なので、必ずこの手順に沿って更新処理を行うようにしてください。
まとめ
ここまでで紹介したrobots.txtテスターの機能は次の3つです。
- robots.txtの構文チェック
- URLがブロックされているかのテスト
- robots.txtの送信
構文チェック機能は人間では気づけないエラーや警告を見つけられ、未然にクロールエラーを防ぐことができるので積極的に活用していきたいですね。
またブロックされたURLを調べたり、robots.txtの送信などのSearch Consoleならではの機能も利用できるのでもし使ったことがないなら利用してみてください。
以上ここではSearch Consoleのrobots.txtテスターの使い方について解説しました。
The post robots.txtテスターの使い方とクロールエラーがないか調べる方法 first appeared on Fukuro Press.
]]>The post robots.txtの役割って何?使い方と書き方を解説 first appeared on Fukuro Press.
]]>
サイト内のあるディレクトリ(フォルダ)やページは検索エンジンの検索結果に表示したくないというときに使われるのが「robots.txt」というファイルです。
これはただのテキストファイルですがここには検索エンジンのクローラーを制御するための特別な命令を書くことでクローラーの動作を制限することが可能です。
ここではrobots.txtにどのような役割があるのかということと具体的な書き方について解説します。
robots.txtの役割
robots.txtの役割は一言でいえば検索エンジンのクローラーに特定のファイルやディレクトリを「クロール」しないように命令することです。
検索エンジンはWeb上にある膨大なページ情報を調べるためにクローラー(またはロボット)というプログラムを使って定期的にWeb上を巡回してページ情報を集めています。
このWeb上のページ情報を集める作業が「クロール」と呼ばれ、クローラーによって集められたページ情報が検索エンジンに伝えられ、データベース上にそのページが登録されることを「インデックスされる」と言います。
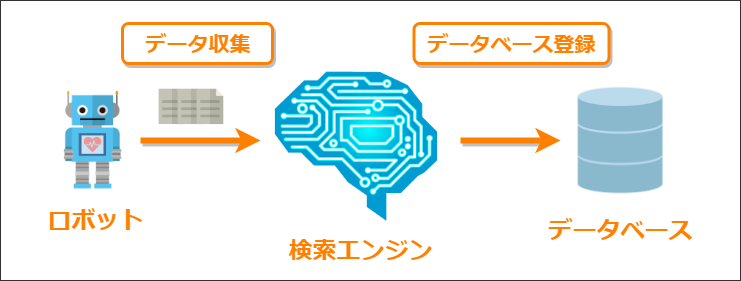
このクローラーへ特定のファイルやディレクトリのクロールをブロックするのがrobots.txtというファイルの役割です。
ではクロールをブロックすることで何の役に立つかというと次のような利点があります。
- 自動生成される質の低いコンテンツのインデックスを防げる
カテゴリごとやタグごとのまとめページはGoogleにとって質の悪いページとみなされるのでそれらをインデックスすることを回避できる
- 検索結果に特定のページを表示させないことができる
どうしても検索結果に表示したくないページがある場合はそのページを検索結果から除外することも可能
- 効率よくクロールさせることができる
無駄なファイルやディレクトリを除外することで効率よくクロールしてもらえる
このように質の悪いページや検索結果に表示したくないページをクロール対象から除外し、クローラーが効率よくクロールできるように助けるのがrobots.txtの役割です。
robots.txtの書き方・構文
クローラーに正しい命令を出すための正しいrobots.txtのルールや構文は次の通りです。
設置場所
まずrobots.txtは必ずサイトのルートディレクトリに「robots.txt」という名前で設置しなくてはなりません。文字コードはUTF-8に設定しておくと安全です。
それ以外のサブディレクトリなどに設置してもクローラーには正しく認識されないので注意しましょう。
正しい設置例
間違った設置例
またrobots.txtにクローラーがアクセスできなくてはならないのでrobots.txtにアクセス制限がかかっていないかのチェックも必要です。
基本の書き方
robots.txtでは次の2行が命令の最小単位になります。
User-Agent: *
Disallow:
まず「User-Agent」にクローラーの種類、その次の行で「Disallow」でクローラーに対してクロールを許可したくないファイルやディレクトリのURLを指定します。
robots.txtではこの2つの行がクロールへの1つの命令として扱われ、複数の命令を書くことが可能です。
User-Agentの書き方
クローラー指定するためのUser-Agentにはクロールをブロックしたい検索エンジンのクローラー名を記述します。
例えばGoogleのクローラーをブロックする場合は次のように記述します。
検索エンジンごとにクローラーの名前は違うので特定のクローラーをブロックしたい場合はまずその名前を調べる必要があります。
また検索エンジンごとでも用途に応じたクローラーが複数巡回していて、たとえばGoogleの場合は次にページで紹介されているように画像用や広告用などで複数のクローラーが動いています。
https://support.google.com/webmasters/answer/1061943?hl=ja
もし特定のクローラーではなく全てのクローラーに対してブロックしたいなら次のように「*」を使われます。
Disallowの書き方
robots.txt内でDisallowの後にファイルやディレクトリのパスを書くとUser-Agentで指定したクローラーに対してそのファイルやフォルダをクロール対象から外すことができます。
この書き方には次のようなルールがあります。
全てのファイル・ディレクトリをブロック
サイト内にある全てのファイルを全てのクローラーに対してブロックしたい場合はDisallowのあとに「/」を書きます。
Disallow: /
これでサイト全体がクローラーにクロールされず検索エンジンにもインデックスされないようになります。
ディレクトリのブロック
特定のディレクトリとその中にある全てのファイル・ディレクトリをブロックしたい場合はDisallowの後に「/[ディレクトリ名]/」のように記述します。
例えばルートディレクトリのすぐ下にある「xxx」というサブディレクトリ全てのファイルやを全てのクローラーに対してブロックしたいなら次のように書きます。
robots.txtの記述例
Disallow: /example/
ブロックされるURL例
xxx.com/example/index.php
xxx.com/example/subdir/index.php
複数ディレクトリをブロック対象に含めたい場合は次のようにDisallowを複数行にわたって書くことでそれらのディレクトリ内のファイルとディレクトリをブロック可能です。
robots.txtの記述例
Disallow: /example1/
Disallow: /example2/
Disallow: /example3/
また次のように最後の「/」がない場合はその名前から始まる全てのファイルとディレクトリがブロックされるようになります。
robots.txtの記述例
Disallow: /ex
ブロックされるURL例
example.com/example.html/
example.com/example-1.png/
最後のスラッシュ「/」があるとないとでは意味が大きく違ってしまうのでスラッシュの有無には注意が必要です。
サブディレクトリのブロック
もし2階層以上のサブディレクトリを指定する場合は「/」の後にそのディレクトリのルートディレクトリに対する相対パスを記述します。
例えばルートディレクトリの下にある「/example/subdir」というディレクトリを全てのクローラーに対してブロックする場合は次のような記述になります。
robots.txtの記述例
Disallow: /example/subdir/
ブロックされるURL例
xxx.com/example/subdir/index.php
以上がrobots.txtの書き方の基本的なルールです。
robots.txtのテストに便利なツール
robots.txtにはこのように決まった書き方(構文)があります。
なので正しく動作させるには必ずその構文に沿って書かないといけません。
でもrobots.txtの構文を初めから完璧に覚えるなんて大変ですよね。
そんな時に役立つのが「robots.txtテスター」というツール
これはSearch Consoleの一機能で、次の画像のように文法ミスを指摘してくれます。
またURLのブロックのテストする機能などもあって本当に便利です。
詳しい使い方については次の記事でまとめたのでご覧ください。

robots.txtの文法チェックやURLのブロックテストのやり方を解説しました。
まとめ
検索エンジンに表示させたくないページがあったり、クローラーが効率よくクロールを行えるようにするのにrobots.txtは役立ちます。
ただクローラーの指定やどのファイルやディレクトリをブロックするかの命令には厳密なルールがあるので構文を間違えずに正しく記述することが大事です。
以上ここではrobots.txtの役割と書き方についてでした。
The post robots.txtの役割って何?使い方と書き方を解説 first appeared on Fukuro Press.
]]>